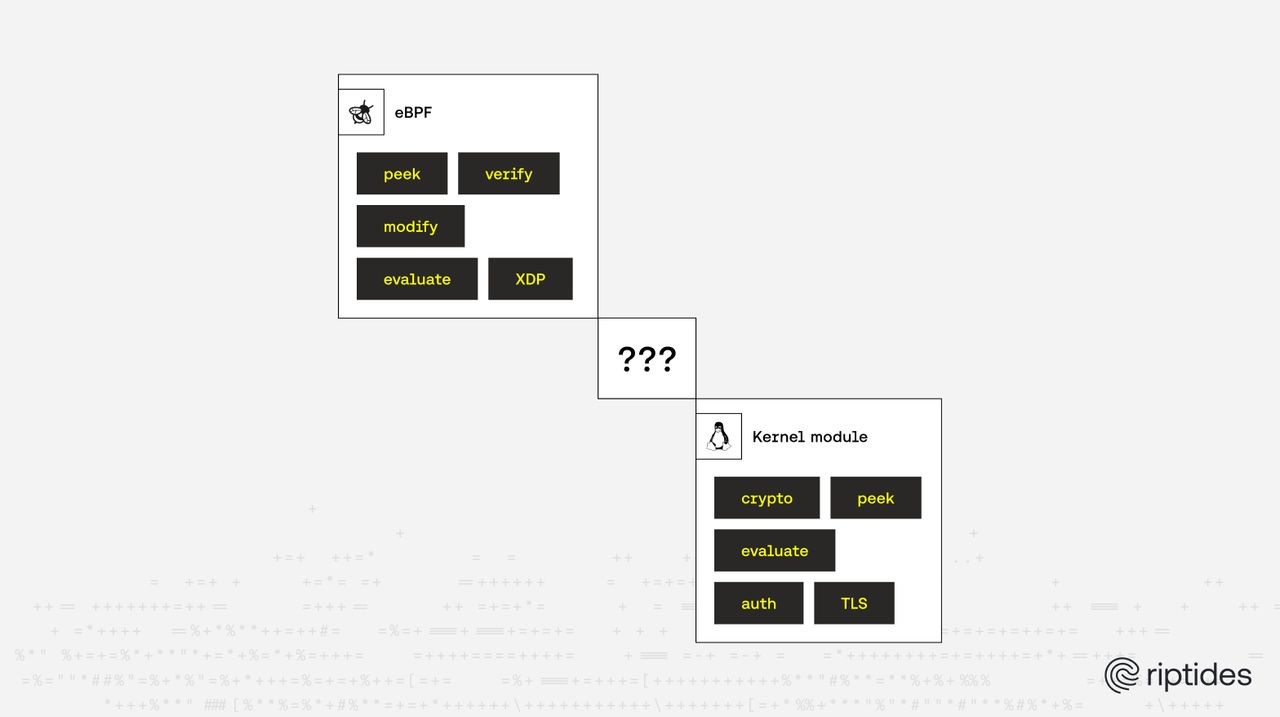
The Core Question: Do We Really Need a Kernel Module?
TL;DR: eBPF is perfect for watching and shaping packets, but when you need to create, sign, and protect the identities behind them, you need the kernel itself.
Whenever we explain Riptides to customers, at conferences or meetups, there’s always one question: “Why a kernel module instead of eBPF?”
It’s a fair one, as eBPF has transformed observability and network control in Linux. It’s safe, flexible, and powerful for tracing, filtering, and enforcing lightweight policies. But when it comes to cryptography, identity, and deep kernel integration, eBPF’s sandboxed nature becomes a limiting factor. This post breaks down that choice - why Riptides runs a kernel module instead of eBPF, what that enables us to do, and what eBPF’s sandboxed model still can’t. We’ll look at concrete use cases as key generation, TLS orchestration, credential injection, and just-in-time credential delivery and show where eBPF reaches its limits.
Our kernel module operates at the TCP layer and intercepts incoming/outgoing connections. It issues ephemeral X.509 certificates and binds those keys/certs to the process that initiated the connection. On a new TCP connection the driver:
- checks destination and policy,
- initiates a TLS handshake,
- establishes kTLS for data-in-transit (when appropriate).
Since enterprises today are tightly coupled with cloud providers, external federation—enabling systems to trust identities without long-lived secrets—is critical. We’ve written why cloud-native federation isn’t enough for non-human identities, but in short: workloads often authenticate with short-lived ID tokens from external providers. These tokens must be securely retrieved and rotated. While cloud providers offer SDKs and tools, they still require a root secret to bootstrap token retrieval, leaving gaps in distribution and isolation.
Riptides solves this in two ways:
- Dynamic sysfs delivery - expose credentials just-in-time via sysfs, scoped so only the intended workload can read them exactly when needed.
- On-the-wire injection - replace auth headers with valid short-lived credentials at the point of egress, transparently to the application.
What We Do at Riptides
Riptides is the non-human identity fabric for workloads and AI agents. We eliminate credential sprawl by issuing and rotating short-lived SPIFFE based identities automatically, moving access control from the network to the workload using familiar primitives — X.509 certs, JWT tokens, TLS, etc - without requiring application changes.
A good technical overview of our solution is described in the Seamless Kernel-Based Non-Human Identity with kTLS and SPIFFE post
Our architecture consists of both a kernel module and a user-space agent. The kernel module operates at the TCP layer, intercepting new connections. When a workload innitiates a connection, the kernel module:
- validates the destination and policy,
- performs a TLS handshake,
- and enables kTLS for encryption at the record layer.
Riptides issues ephemeral X.509 certificates and binds them to the process that initiated the connection, ensuring that identities are both short-lived and process-scoped. As most enterprises today use cloud providers, federation is critical as well. Riptides can also federate accross cloud providers, or inject secrets/credentials towards 3rd parties, without needing a bootstrap secret. We do this in two different ways:
- Dynamic sysfs delivery: credentials are exposed just-in-time through sysfs, scoped to the requesting workload only.
- On-the-wire injection: by transparently replacing outbound authentication headers with short-lived credentials, so applications never handle them directly.
Some of The Key Tasks We Handle
- Asymmetric key and certificate generation (keys, CSRs, certs)
- TLS handshake orchestration and kTLS enablement
- On-the-wire credential injection (signing and header replacement)
- Just-in-time credential exposure via sysfs
Kernel-based solutions (what we implemented and why)
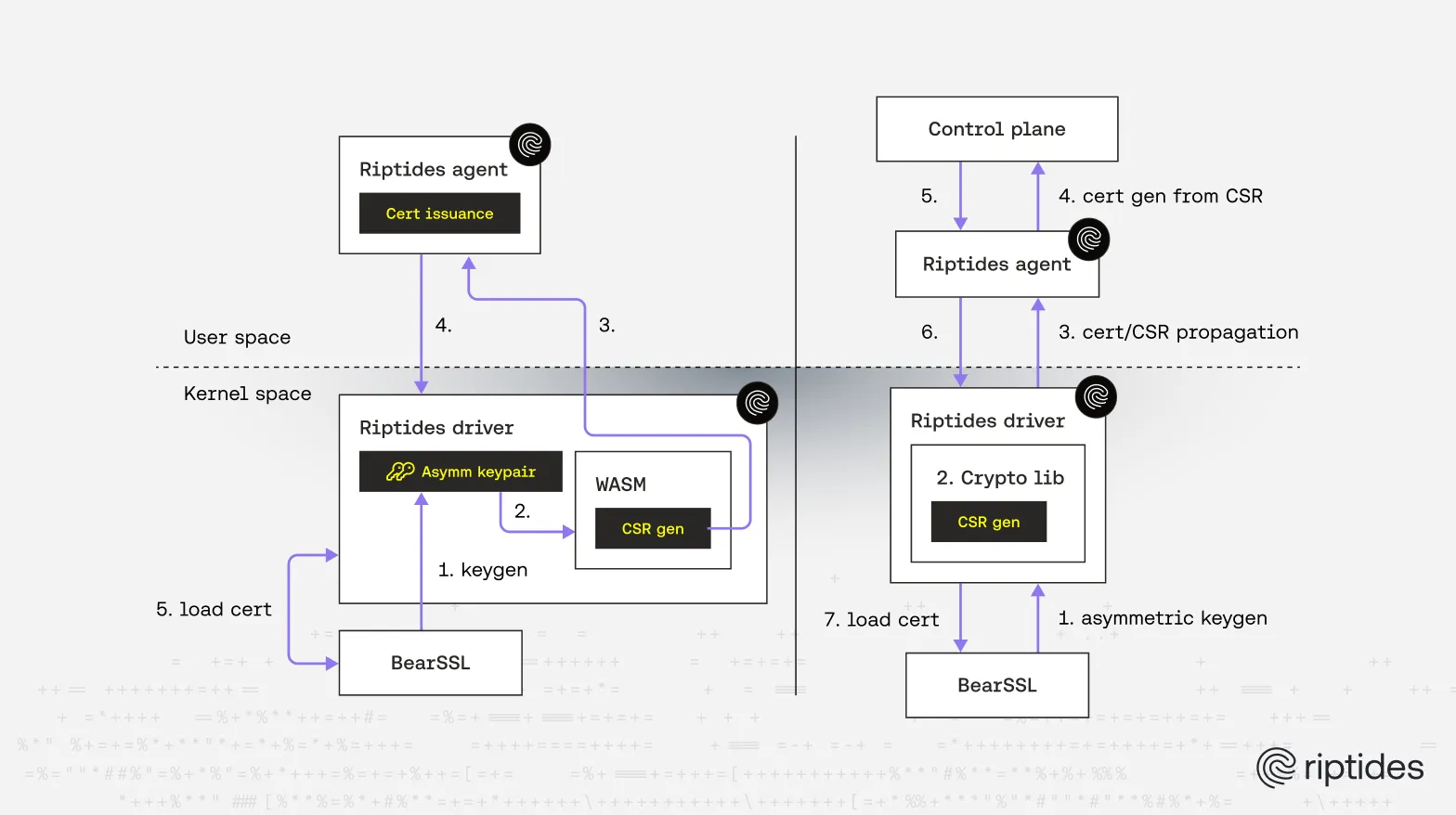
Certificate generation (keys, CSR, certs)
The Linux kernel crypto API provides certificate generation or big-integer asymmetric key generation. The asymmetric-key subsystem expects keys to be supplied/loaded from userspace — i.e., the kernel API can sign/verify with a key that’s already present, or create a signature blob (create_signature), but it won’t create RSA/ECDSA keypairs or produce CSRs for you.
We needed in-kernel key generation to tightly bind identities to processes and to avoid exposing long-lived private material in userspace. Instead of reinventing crypto primitives, we ported a small crypto library to run inside the kernel:
- initially we ported BearSSL (adapting libc usage to kernel headers), which gave us asymmetric keypair generation inside the kernel. BearSSL is compact and suitable for constrained environments.
- we experimented with a tiny WebAssembly approach to produce CSRs in a sandboxed way (CSR generation in WASM and PEM output to userspace). That gave us a separation boundary, but we later refactored away from in-kernel WASM for security and complexity reasons — see our blogpost From Kernel WASM to user-space policy evaluation. - and moved to supporting native CSR and certificate generation within the kernel.
We keep CSR issuance in the control plane (userspace CA or external CA) but generate keys and create CSRs in privileged kernel context so private material never leaves the kernel memory.
TLS Handshake
At the time of publishing this blogpost, the kernel crypto API is unable to handle TLS handshake directly inside the kernel. There was/is a debate on the mailing list whether implement the TLS 1.3 handshake inside the kernel.
kTLS exists in Linux but it handles only the record layer - encryption/decryption of TLS records - not the full handshake. The kernel networking stack offers a handshake offload API: a socket file descriptor can be passed to a userspace handshake agent (via netlink), the agent completes the handshake, then returns the socket back to the kernel and sets the TLS ULP (userland handshake model). Projects like Oracle’s ktls-utils show that pattern in practice. Others like Tempesta releasing tech studies about the performance of the handshake happening inside the kernel.
We chose the second approach for Riptides: we perform the TLS handshake inside the kernel module using the in-kernel crypto stack that we ported. Doing the handshake inside the kernel:
- lets us bind cert/key lifecycle to kernel object lifecycle and to process context,
- allows immediate kTLS activation, avoiding round trips to the user agent during connection setup,
- simplifies transparent on-the-wire credential replacement because we control both handshake and record protection.
On-the-wire credential injection
We need to inject or replace authentication headers (for AWS, GCP, etc.) so workloads never hold long-lived cloud credentials. To do this transparently we must:
- reliably attribute a connection to a specific process (the principal authorized to obtain/consume credentials),
- access plaintext application bytes before encryption (or terminate/reinitiate when encrypted), and
- compute any provider-specific signatures (AWS V4 signing, etc.) and rewrite headers.
I am not going to dive into all the details if you are interested check out our blogpost about credential injection.
Implementation highlights:
- the module inspects outbound buffers, since we manage TLS end-to-end we can peek at plaintext before encryption.
- if an application already encrypted its data in userspace (so we only see ciphertext), Riptides terminates the connection and reinitiates it using ephemeral credentials under our control, then performs the injection. This is transparent to the client.
- header rewriting requires robust HTTP parsing and stateful handling because application payloads may span multiple packets/segments. The kernel module keeps the necessary per-connection state to reconstruct requests where needed.
- for provider flows that require extra signing (e.g., AWS signed headers), we compute the signatures dynamically in the kernel and replace the client’s header with a freshly signed one.
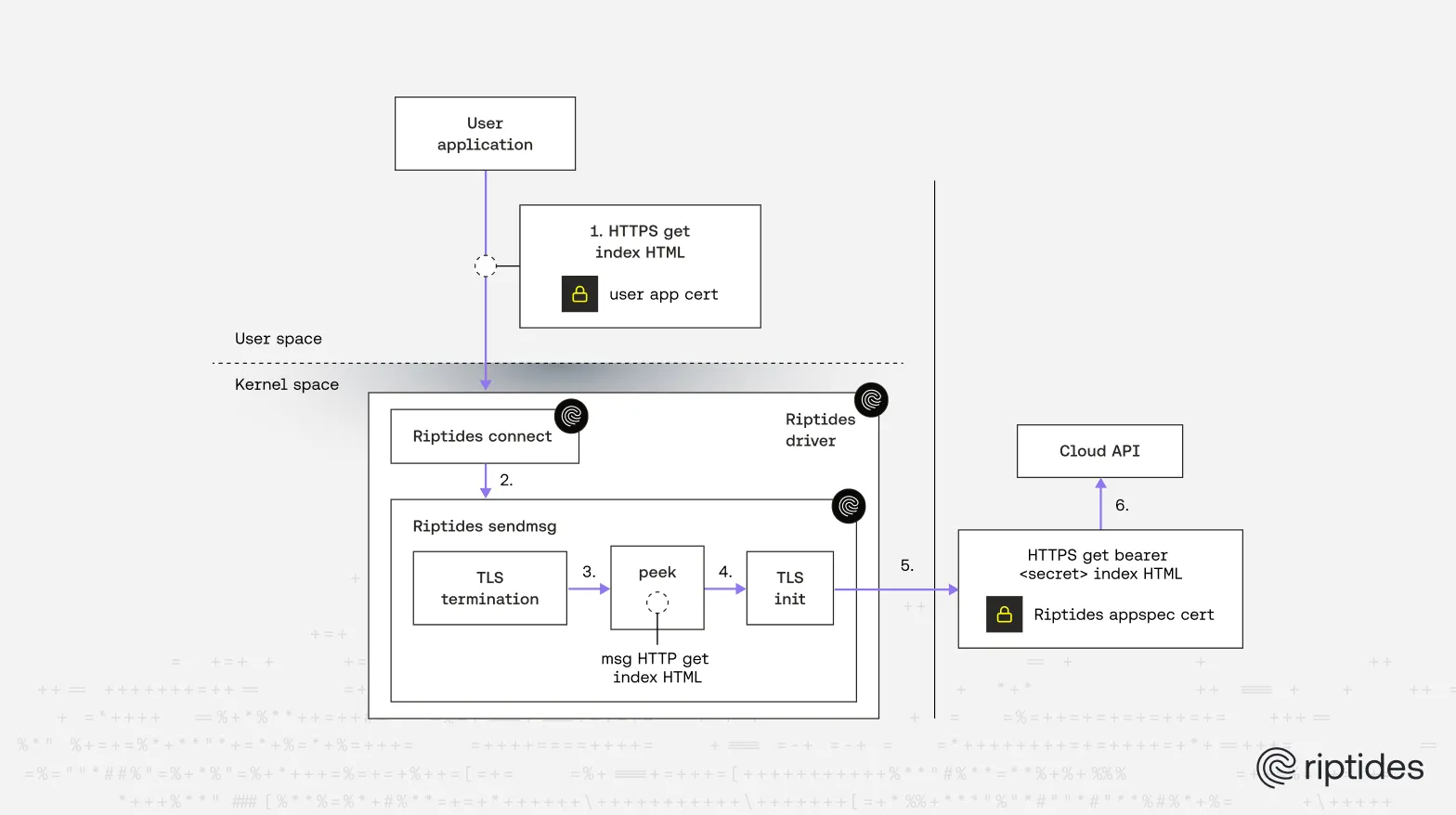
Data is encrypted in user space.
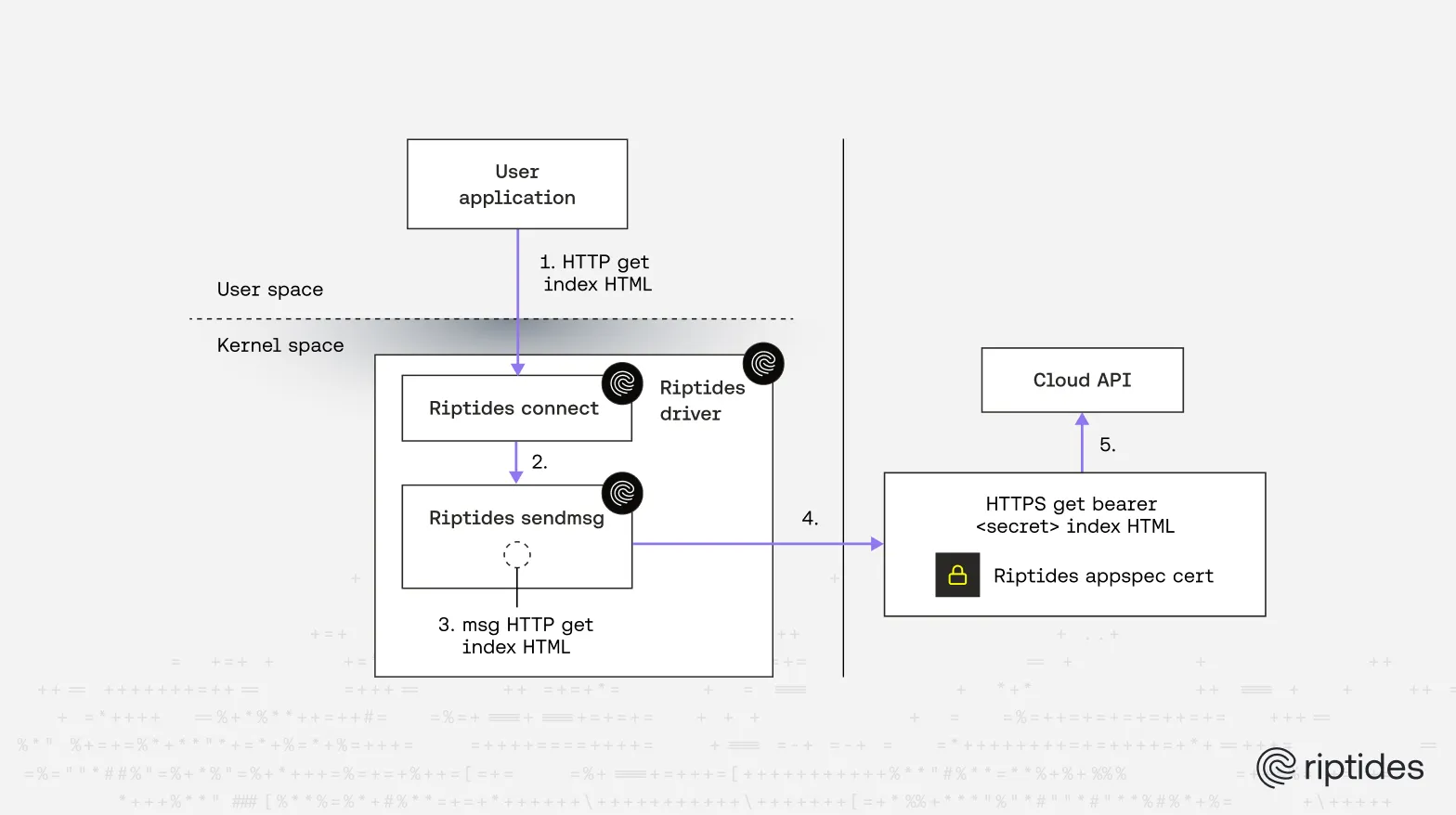
Plaintext data from user space
This is complex, but feasible in kernel space because we control handshake, keys, and send hooks.
Credential exposure via sysfs:
Acourding to linux manual page, sysfs is a kernel pseudo-filesystem exposing kernel objects. Riptides uses sysfs to present short-lived credentials just-in-time to a workload: the kernel module creates sysfs nodes with appropriate access controls and serves credentials such that only the requesting process can open/read them at the allowed time window.
Creating scoped sysfs entries and enforcing in-kernel access control is straightforward within a kernel module, let’s see how all these problems could be solved from eBPF.
eBPF-based solutions - what eBPF can and cannot do
eBPF is powerful for observability and safe programmability, but it runs in a sandbox with limited helpers and no arbitrary filesystem / crypto capabilities. Below I keep the same problems and discuss eBPF options and gaps.
Certificate generation
eBPF cannot generate asymmetric keypairs or produce CSRs/certs. It lacks the math libraries, heap, and API surface required for big-integer crypto operations, and you cannot realistically port an SSL/TLS stack into eBPF. So certificate/key generation must remain in userspace, with keys shared to eBPF only in limited forms (if at all).
TLS handshake
eBPF cannot implement a TLS handshake. Handshake logic requires stateful complex crypto and network interactions far beyond eBPF’s intended use. The kernel provides only the record-layer kTLS facilities, handshake must be performed by a TLS library (userspace or kernel). eBPF’s strength here is observation - not managing TLS state machines.
On-the-wire injection
With eBPF we can also observe user data sent over the wire — this is very much eBPF’s territory. It offers multiple options, the main difference between them is where the inspection happens. Unfortunately there is no silver-bullet: a program that can inspect encrypted data generally cannot modify it, so we often need to transfer context between eBPF programs or combine eBPF with other mechanisms. eBPF hooks differ significantly depending on where they attach in the stack: we move from as close to the hardware as possible up to the user application.
XDP(eXpress Data Path) - earliest interception
XDP runs at the network device driver level and processes each incoming packet before it reaches the kernel networking stack, so it provides the highest performance with minimal overhead. Its primary use cases are things like DDoS protection (for example, Cloudflare has used XDP eBPF programs for large-scale mitigation) and high-performance filtering.
In a nutshell, XDP programs return one of several actions that indicate what the kernel should do next:
- XDP_PASS: pass the packet up the networking stack (optionally after in-place modification)
- XDP_TX: resend the packet back to the same network port where it arrived on.
- XDP_REDIRECT: redirects the packet to a different location. The location could be a different networking interface or a different CPU, or to the user-space.
- XDP_ABORTED: used for debugging, triggers an exception and a trace log entry.
- XDP_DROP: drop the packet.
Because XDP operates at such a low level, parsing application-layer protocols (essential for HTTP header injection) is error prone and difficult. XDP runs on raw frames and processes packets individually, so reconstructing and parsing a complete HTTP request often requires complex, manual TCP reassembly and state handling when the data spans multiple segments.
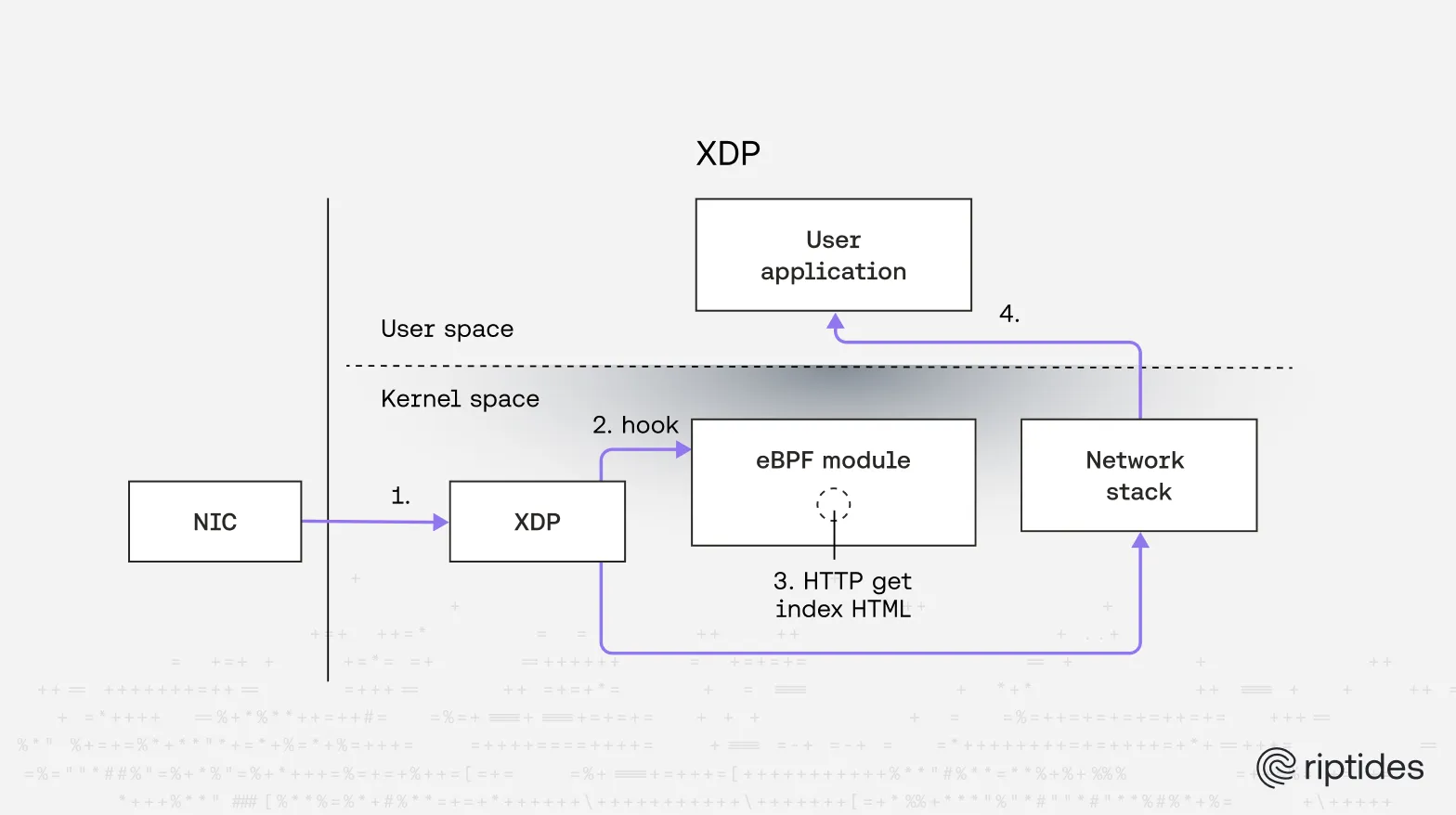
Theoretically, if parsing succeeds, we then need to modify the HTTP header — which could be done in an XDP program. However, XDP provides no checksum or socket helpers, so everything must be implemented by hand. Implementing a certificate-signing mechanism here (essential for providers like Amazon) is effectively impossible in practice. For these reasons, performing L7 data processing at the XDP level is not recommended.
Socket Filter - Application-level interception
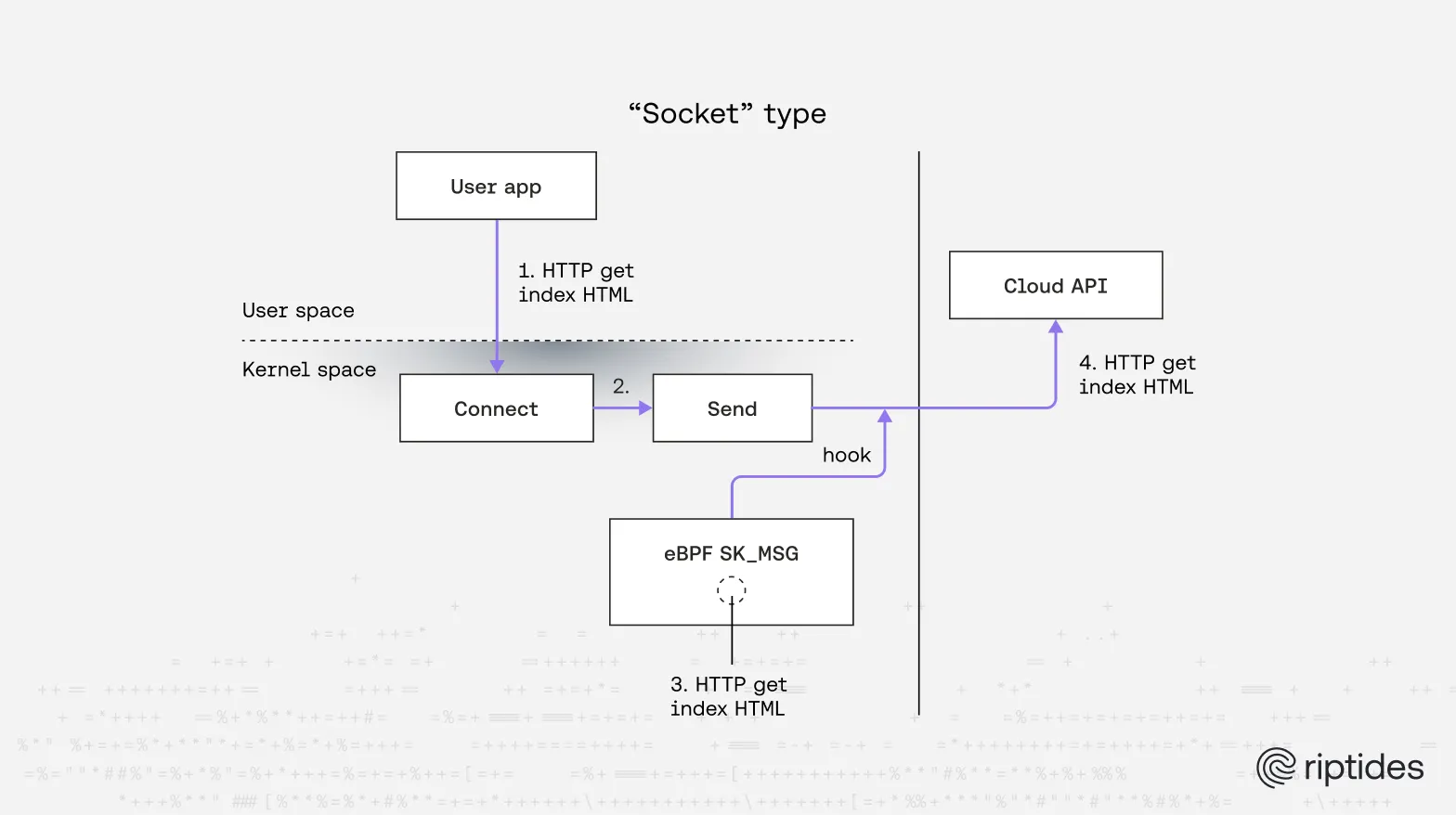
Moving up the stack, socket filters run after the kernel networking stack has processed packets, so they see complete packet data and are a much better fit for HTTP parsing and header modification. We can distinguish four relevant eBPF socket attach types:
- Socket filter: the original Linux Socket Filter (derived from BSD BPF). A filter is attached to a specific socket via
setsockopt. It runs on packets delivered to that socket and decides how many bytes to accept or drop before data reaches the socket’s receive queue. Think of it like an in-kernel tcpdump-style filter. - SK_SKB (socket buffer programs on SOCKMAP/SOCKHASH): They are sit on TCP data streams to parse application level(L7) messages and with that make decision wheter it is allowed or blocked or redirected. It works on SOCKMAP/HASH which is an unique map type which holds network sockets as values. SKP programs have different purposes based on their attach type. It could be Parsers or Verdict programs.
- SK_MSG (send-path verdict on SOCKMAP/SOCKHASH): This is a verdict program for outbound messages on the socket sits inside the SOCKMAP/SOCKHASH. It inspects application data before it leaves the socket and can pass/drop or redirect to another socket via map helpers. Complements SK_SKB for receive-side control.
- SOCK_OPS: Lifecycle and event callbacks for TCP sockets (e.g., state changes, established, timeouts) typically attached at a cgroup, great for enrolling/removing sockets in SOCKMAP/SOCKHASH and tuning per-connection behavior. It is not suitable for filter purposes.
or HTTP parsing and reliable header modification the best eBPF approach is a combination of SK_SKB (receive-side parsing) and SK_MSG (send-side verdicts/rewrites). Because these hooks run after TCP reassembly, they can operate on higher-level application payloads and redirect to a peer socket that performs full header rewrites or injection. One important limitation: these hooks only see plaintext if encryption happens after the hook point. If the application performs TLS entirely in user space, the eBPF program will only see ciphertext and cannot decrypt it. Fortunately, many common user-space TLS libraries support kTLS , which moves record protection into the kernel so eBPF hooks placed before the kernel’s record-layer encryption can peek at plaintext.
KProbes/UProbes
In our tracing blogposts we explained how Kprobes work, here we’ll focus on Uprobes because they offer a unique approach for tracing encrypted messages. Uprobes are dynamic, per-process instrumentation points that attach to user-space function entry and exit without modifying binaries. They let you observe function arguments, return values, and relevant memory in the probed process with minimal overhead.
This makes Uprobes ideal for parsing application-layer data at functions such as SSL_write and SSL_read. SSL_write sees plaintext application bytes before encryption, and SSL_read sees plaintext after decryption, so an attached uprobe can reliably parse HTTP headers, URIs, or custom protocols. Using Uprobes bypasses the limitation of kernel-level socket hooks - which only observe ciphertext when encryption happens in user space — and provides deep observability with precise process attribution.
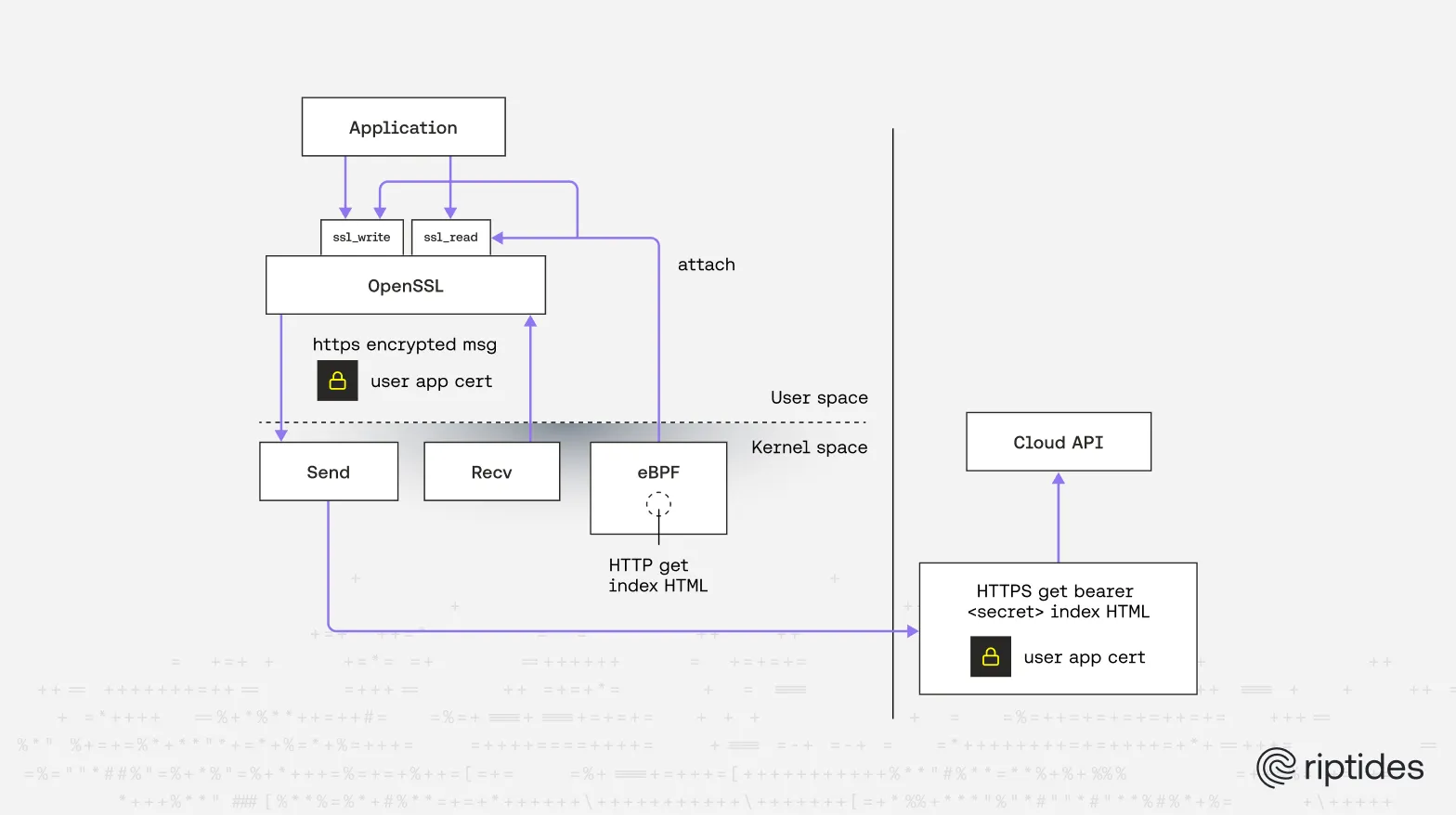
Relying on Uprobes lets us parse payloads in a reliable way, but there are caveats. Uprobes typically depend on specific function names and calling conventions, so they work only for particular library versions (e.g., a given OpenSSL release). Other TLS libraries (LibreSSL, BoringSSL, GnuTLS, custom vendored stacks) expose different functions and memory layouts that require different Uprobe locations and handling. Supporting every library and every version is therefore non-trivial and becomes a long-term maintenance effort, but Uprobes remain a powerful additional tool when you can target a known runtime.
Credential exposure via sysfs:
An eBPF program cannot create files in sysfs (or anywhere in the filesystem). eBPF runs in a heavily restricted, sandboxed environment with no direct ability to perform arbitrary filesystem operations like creating files, opening paths, or writing to virtual filesystems such as sysfs. It can only interact through approved helpers, maps, and event output mechanisms, none of which allow creating sysfs nodes.
Conclusion
Riptides’ mission requires tight integration between cryptography, policy enforcement, and workload identity — all within the Linux kernel’s trust boundary. eBPF gives developers safe, dynamic programmability for observability, filtering, and lightweight policy logic, but its sandbox stops at the edge of cryptographic and filesystem operations. In contrast, kernel modules give us:
- direct access to the crypto stack and socket lifecycle,
- process-bound identity binding,
- transparent credential orchestration,
- and low-latency, in-kernel TLS activation.
In short: eBPF is perfect for watching and shaping packets, but when you need to create, sign, and protect the identities behind them, you need the kernel itself.
If you enjoyed this post, follow us on LinkedIn and X for more updates. If you'd like to see Riptides in action, get in touch with us for a demo.