Evolving our build system for multi-distro, multi-kernel automation
Riptides issues SPIFFE-based identities directly from the Linux kernel, securing workload communication at the system’s lowest boundary. To make that possible across diverse environments, our kernel modules must build fast and reliably for a wide range of distributions and versions. In our previous blog post, Building Linux Driver at Scale: Our Automated Multi-Distro, Multi-Arch Build Pipeline, we shared how we have built a fully automated pipeline to compile our kernel module across multiple distributions and architectures. As we expanded our supported kernels and distributions, we quickly hit GitHub Actions’ scaling limits. This post dives into how we overcame those challenges and pushed our build automation even further.
The First Challenge: Kernel Headers and Scale
Building a kernel module is never “one-size-fits-all.” Each distribution and kernel version requires its own kernel-headers or kernel-devel package.
That means the same code must be compiled hundreds of times, and each time inside the matching environment for that kernel.
Over time, our build matrix exploded:
- Multiple distributions (Ubuntu, Fedora, Debian, CentOS, Amazon Linux, etc.)
- Multiple versions per distribution
- Multiple architectures (x86_64, aarch64)
- Multiple kernel versions for each combination
This quickly exceeded GitHub Actions’ limits:
- Maximum 256 matrix jobs per workflow run
- Maximum 1 MB output per job
- Maximum 50 MB total outputs per workflow run
For a project that compiles hundreds of kernel modules, these limits became a real bottleneck.
Our First Attempt: One Giant Matrix
Initially, we generated a single large build matrix containing every possible combination. This worked well until we crossed 256 jobs, GitHub Actions simply refused to run more. Even when we tried to split by architecture or distribution, outputs from large jobs (such as build metadata and artifact paths) began hitting the 1 MB per-job output limit.
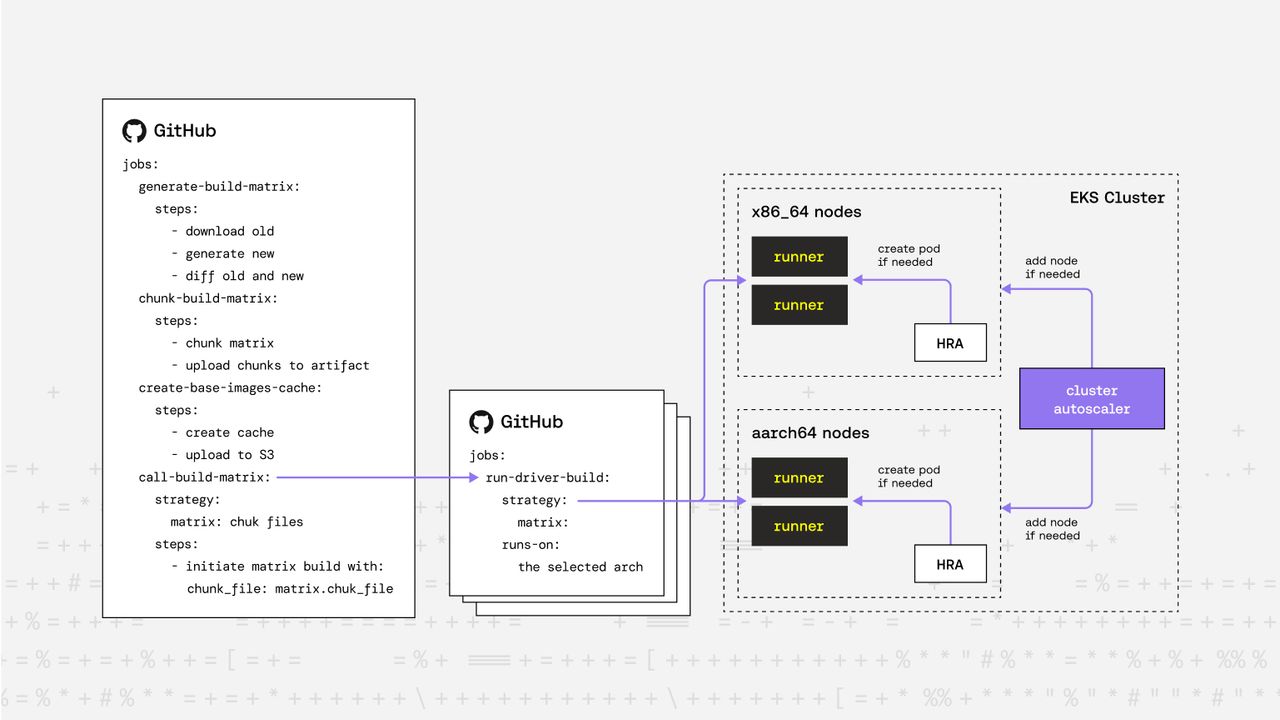
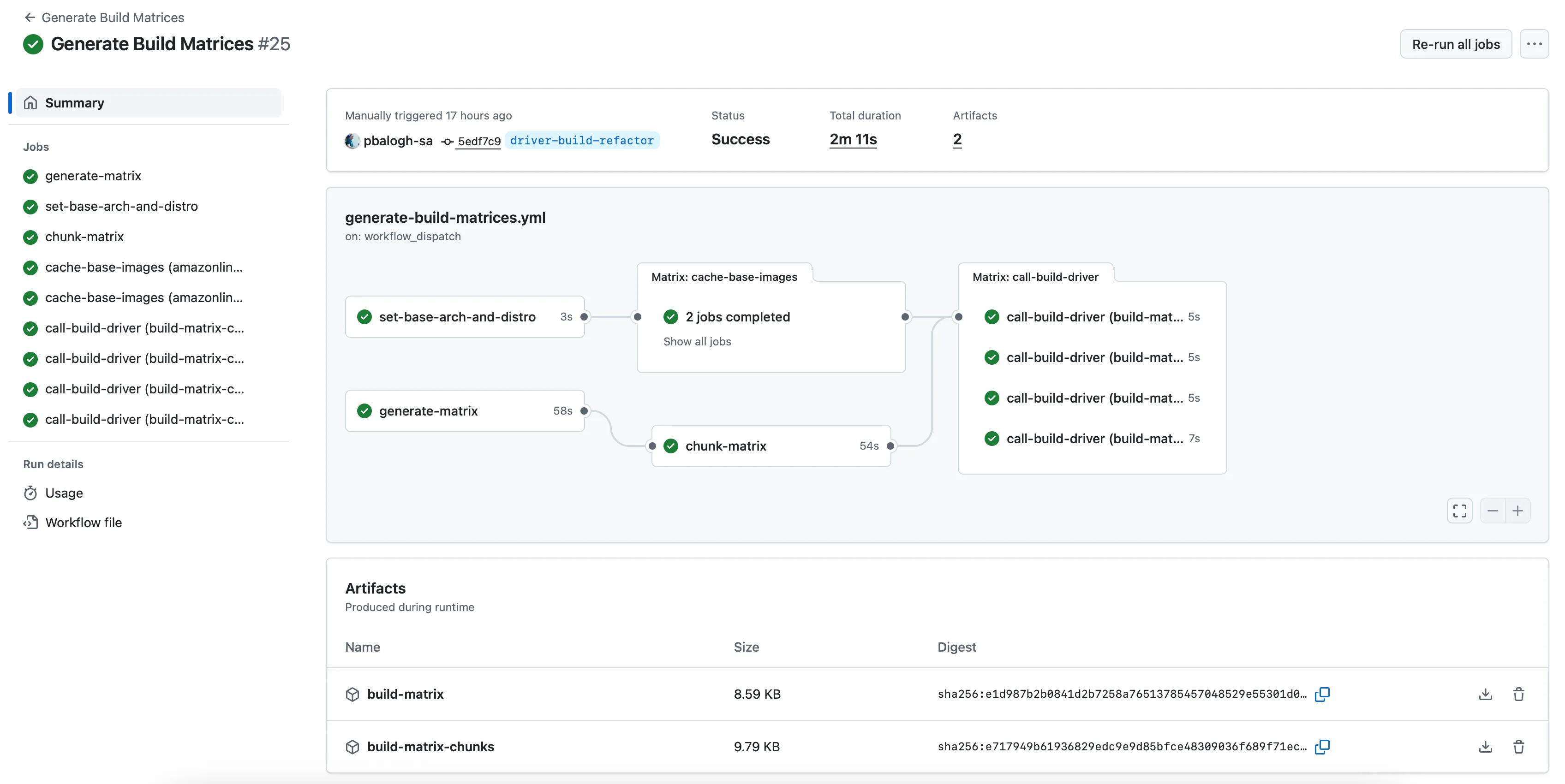
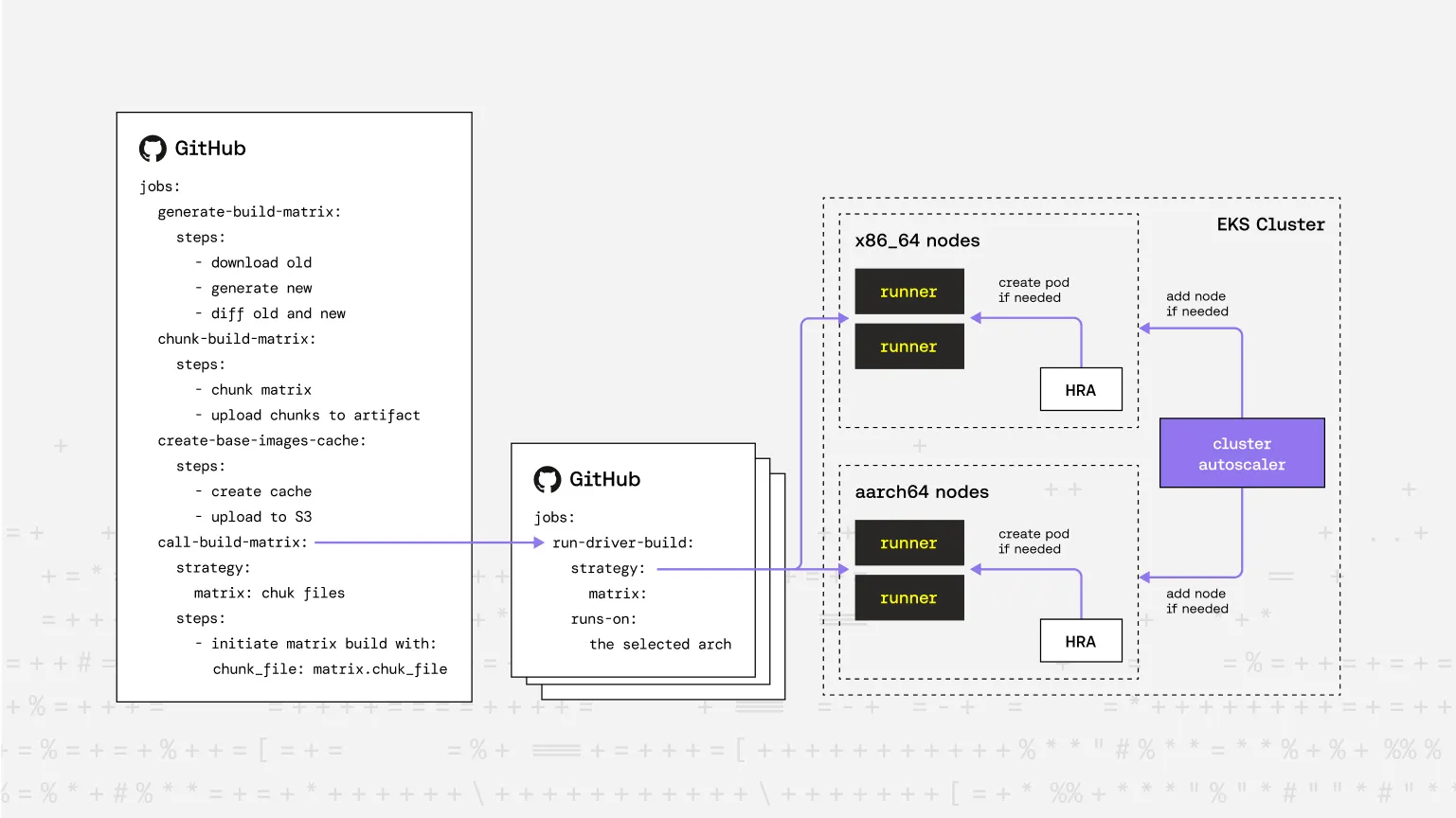
Breaking the Barrier: Matrix Chunking + Workflow Dispatch
To overcome these limitations, we rearchitected our pipeline into two workflows.
1. The “Matrix Generator” Workflow:
- Generates the full build matrix dynamically (based on available kernel versions and distributions)
- For incremental builds, diffs the newly generated matrix with the previously used one (downloaded from an S3 bucket)
- Chunks the effective matrix into smaller JSON segments (e.g., batches of 50)
- Triggers multiple child workflows via
workflow_dispatch, each with one matrix chunk
Each chunk represents a manageable set of builds that stay well within GitHub’s job limits.
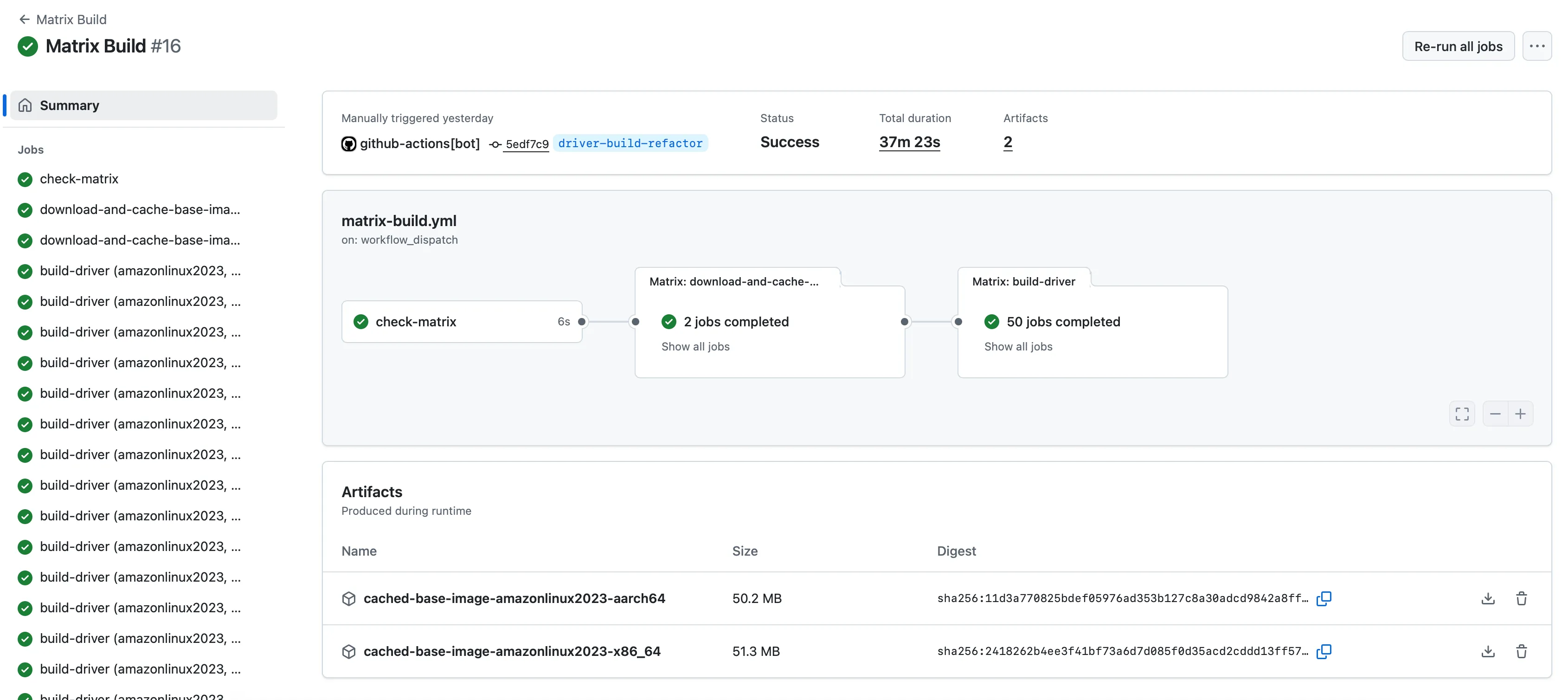
2. The “Matrix Build” Workflow:
The second workflow is invoked by the “Matrix Generator.”
It reads the matrix chunk, creates the strategy.matrix dynamically, and performs the actual kernel module builds.
This distributed approach scales virtually without limit.
We can trigger up to 256 child workflows, which means the theoretical maximum number of kernel module builds is 256 x 256 = 65536 — far beyond what we currently need.
The Second Challenge: Container Registry Rate Limits
During large-scale builds, we also encountered rate limits from container registries. Fetching hundreds of base images in parallel is both expensive and slow, especially when each job pulls the same image layers.
Breaking the Barrier: Custom Container Image Caching Layer
- The “Matrix Generator” workflow builds our own base images (for each distro and architecture) if an image hasn’t already been built and uploaded to the S3 bucket.
- These base images are saved as tarballs and uploaded to the S3 bucket.
- The “Matrix Build” workflows then download the tarballs from S3 only once and upload them as GitHub Artifacts.
- Every parallel build job restores its image from the local artifact (no S3 traffic, no rate limiting).
This drastically reduced build startup time and made the system much more reliable.
+1 Challenge: Missing Kernel Versions
While building for multiple distributions, we realized that some kernel versions weren’t readily available through standard package repositories. Tools like Falco’s kernel-crawler are great for identifying available kernels, but they don’t cover every version we need—especially the latest live-patch kernels from Amazon Linux or Fedora.
Filling the Gaps: Fedora Koji & Amazon Linux Live Patch Packages
To fill these gaps, we started leveraging:
- Fedora Koji build system that provides official Fedora kernel packages for versions that aren’t published in standard repos.
- Amazon Linux live patch packages which is official kernel updates for Amazon Linux 2 and Amazon Linux 2023, including critical security patches.
By pulling the kernel headers and modules directly from these sources, we ensure that our builds cover all supported kernel versions, including those missing from Falco’s kernel-crawler. This step was essential for maintaining full coverage across distributions and staying up-to-date with security updates.
Conclusion
Scaling kernel module builds across dozens of Linux distributions and kernel versions isn’t just about compute power, it’s about architecture. By breaking past GitHub Actions’ native limitations, we built a flexible, distributed system capable of compiling hundreds of kernel variants in parallel, without overloading our CI platform or container registries.
The combination of matrix chunking, workflow chaining, and prebuilt base image caching gave us the control and reliability needed to handle large-scale builds efficiently. This approach now allows our engineering team to iterate faster, validate new kernel releases quickly, and deliver tested drivers for every major Linux environment automatically.
Benefits of the New Design:
| Challenge | Solution | Result |
|---|---|---|
| 256 job workflow limit | Chunked matrix generation | Unlimited scalability |
| Output size limits | Pass JSON chunks | Reliable data exchange |
| Registry rate limiting | Cached tarballs + GitHub artifacts | Faster, stable builds |
| High startup time | Prebuilt base images | Minimal job initialization overhead |
We can now build Riptides kernel modules for hundreds of kernel versions across all major distributions in parallel, using self-hosted runners optimized for kernel compilation.
Key Takeaways:
- Chunk large matrices into smaller workflows to bypass GitHub Actions’ 256 job limit.
- Use
workflow_dispatchorrepository_dispatchevents to trigger child workflows dynamically. - Keep workflow outputs minimal to avoid the 1 MB per-job and 50 MB per-run output caps.
- Cache and reuse base images (as
.tarfiles) to eliminate registry rate-limit issues. - Leverage GitHub Artifacts for fast, local image distribution in parallel jobs.
- Design for scale from the start. A small architectural decisions early on prevent major pipeline bottlenecks later.
Interested in how our Linux kernel journey unfolded and what we learned along the way?
- Rethinking Workload Identity at the Kernel Level
- Riptides: Kernel-Level Identity and Security Reinvented
- From Breakpoints to Tracepoints: An Introduction to Linux Kernel Tracing
- From Tracepoints to Metrics: A journey from kernel to user-space
- Seamless Kernel-Based Non-Human Identity with kTLS and SPIFFE
- Linux kernel module telemetry: beyond the usual suspects
- From Tracepoints to Prometheus: the journey of a kernel event to observability
If you enjoyed this post, follow us on LinkedIn and X for more updates. If you’d like to see Riptides in action, get in touch with us for a demo.
If you enjoyed this post, follow us on LinkedIn and X for more updates. If you'd like to see Riptides in action, get in touch with us for a demo.