Before any workload can speak securely, it must first earn the right to be trusted. At Riptides, we use SPIFFE-based identities, certificate-based authentication, and TLS to secure every connection directly from the Linux kernel, but those mechanisms depend on a deeper layer of truth. Workload attestation is how we verify that a process truly is what it claims to be, before granting it an identity.
What is Workload Attestation?
What is a workload?
At its core, every workload reduces to a running process (or a process tree) inside a Linux system. Whether you call it a container, pod, function, or microservice, underneath it all is a process executing a binary with a particular environment and set of kernel attributes.
However, a workload is not one process — it’s a logical unit of work represented by one or more process instances that share the same operational and semantic identity.
For example:
- The same container image running on 10 Kubernetes nodes produces 10 processes, but they represent one workload in the scheduling and identity sense.
- Each process instance has a unique runtime footprint (PID, namespace, start time, executable hash, etc.), but they all map to the same workload class (same image, same service account, same namespace).
In short: > process = instance > workload = class of instances that perform the same logical function
What is workload attestation?
Workload attestation is the process of collecting verifiable facts about a specific running process instance and presenting those facts as evidence to a policy or issuing component.
The attester answers the question:
“Can I prove, using data the process cannot forge, what this process actually is and where it came from?”
If that evidence matches expected properties (image digest, service account, node posture, etc.), an issuer can confidently bind the workload instance to a short-lived credential (whose subject may later correspond to a SPIFFE ID). For more on how these credentials and certificates are the foundation of trust and fit into our broader identity model, see X.509 Certificates in the Age of SPIFFE and Zero Trust.
The core insight
Even though orchestration frameworks operate at higher layers (pods, deployments, jobs), the root of truth is always process-level evidence, because:
- It’s what the kernel enforces (exec, namespaces, capabilities).
- It’s where identity is realized (socket ownership, TLS sessions).
- It’s the narrowest, most trustworthy observable boundary that can be measured and attested.
You can think of attestation as lifting process-level facts into workload-level context.
Design Goals and Constraints
Why design goals matter
Workload attestation sits at the intersection of systems introspection and trust establishment. It must collect facts from the OS in a way that is reliable, non-forgeable, and reproducible across thousands of process instances. The challenge is to balance fidelity (accuracy of evidence) and feasibility (how safely and efficiently you can collect it).
Determinism: same workload, same evidence
A given workload should produce consistent evidence across its instances — assuming they run the same binary, image, and configuration. Even small runtime differences (binary hash, UID, node) must yield distinct evidence.
This enables:
- Predictable identity derivation (same workload → same logical ID).
- Simple verification (expected vs. actual digest sets).
- Stable trust chains across reproducible deployments.
Collision resistance: prevent false equivalence
Different workloads must not collapse into the same attested identity. Evidence should include entropy from:
- the binary hash,
- the image digest,
- the namespace or service account,
- and the node identity.
Even if two workloads run the same binary, attestation should preserve their contextual distinctness.
Logical isolation must translate into identity isolation.
Minimal privilege, maximal visibility
The attester must observe workloads without becoming an attack surface.
Principles:
- Collect only what’s needed (no raw environment, no secrets, sanitize data).
- Use kernel-exposed views (procfs, sysfs, cgroup, CRI/kubelet).
- Separate collection privileges from policy and issuance.
- Operate in read-only mode whenever possible.
In short: least privilege + read-only + host-level visibility.
Portability and abstraction
The mechanism must generalize across:
- Bare-metal and VM nodes
- Container runtimes (Docker, containerd, CRI-O)
- Orchestrators (Kubernetes, Nomad, ECS)
- Public clouds (AWS, GCP, Azure)
Evidence sources may differ, but the schema — the shape of the collected metadata — must remain stable. This allows one attestation framework to operate uniformly across a heterogeneous fleet.
Operator visibility and auditability
Operators must be able to inspect attestation outcomes:
- Which workloads were attested, when, and on which node.
- What evidence contributed to each decision.
- Why a particular workload failed attestation.
Good observability turns attestation from a black box into a transparent part of the platform’s trust fabric. At Riptides, our kernel-level observability pipeline built on eBPF provides the fine-grained process and network insights that make such transparency possible.
Identifying a Specific Linux Process Instance
Why this matters
At the heart of workload attestation is the ability to say with confidence:
“This evidence corresponds to this exact process instance, and not a recycled or spoofed one.”
Linux reuses PIDs constantly, workloads exec() new binaries in place, and containers mask process hierarchies.
Attestation therefore needs stable, kernel-level identifiers that remain valid across these transitions.
Process instance vs. workload class
A workload represents a logical unit of work that may have many running instances. Each process instance is one concrete execution of that workload — a live entity inside a PID namespace with its own start time and binary.
Attestation always begins with the process because it’s the smallest, verifiable boundary the kernel exposes. Every higher-level concept (container, pod) ultimately maps back to a process.
Stable, non-forgeable identifiers
The goal is to derive a small set of immutable facts that uniquely identify one process instance even if its PID is reused later.
| Category | Source | Example / Field | Purpose |
|---|---|---|---|
| Namespace identity | /proc/<pid>/ns/pid | inode number | Distinguishes processes across PID namespaces |
| Start time | /proc/<pid>/stat field 22 | jiffies since boot | Differentiates reused PIDs |
| Executable identity | /proc/<pid>/exe (opened fd) | SHA-256 of ELF | Code identity, stable even if file unlinked |
| User context | /proc/<pid>/status | uid, gid, name | Links workload to execution context |
| Command shape | /proc/<pid>/cmdline (sanitized) | argument vector | Optional — helps correlate replicas |
Additional discriminators (optional)
- Cgroup path (
/proc/<pid>/cgroup) – maps the process to its container or pod context. - Mount namespace inode (
/proc/<pid>/ns/mnt) – distinguishes isolated filesystem views. - Capabilities (
CapEffin/proc/<pid>/status) – captures runtime privilege set.
These can enrich the evidence set.
Interpreted languages and dynamic runtimes
Hashing an executable ELF file works perfectly for statically linked or compiled binaries, but not for interpreted languages such as Python, Node.js, Ruby, or Java. In these cases, the ELF you hash is only the interpreter, not the code actually being executed.
To improve accuracy:
- Include script or bytecode hashes when the file is accessible on disk.
- Record the interpreter command line (e.g.,
/usr/bin/python3 app.py) in sanitized form. - Observe loaded modules or JARs when feasible; their digests often carry semantic identity.
- Treat the container or image digest as the stronger code anchor when the runtime dynamically loads code.
Interpreted workloads therefore rely more on environmental evidence (image digest, orchestrator metadata) than on the ELF hash itself. Attestation systems must recognize this distinction and adjust policy accordingly.
Collecting Environmental Evidence
From process to environment
A process on its own tells you what is executing, but not where or under what circumstances. To transform low-level process identity into a workload identity candidate, we must capture contextual evidence, the environmental signals that surround the process.
This includes:
- Container and image information (what packaged artifact is running),
- Orchestrator metadata (what the scheduler declared),
- Node and OS provenance (where it runs physically or virtually),
- and optionally Cloud instance metadata (which management domain or project it belongs to).
Container and runtime evidence
Containers are the most common abstraction boundary between the orchestrator and the process. They provide deterministic packaging, but also hide process details. Therefore, an attester must be able to map a process → container → image digest relationship.
| Source | Example | Notes |
|---|---|---|
/proc/<pid>/cgroup | 0::/kubepods.slice/.../docker-abcdef.scope | Identify container runtime and ID |
| Container runtime API (Docker, containerd, CRI) | container.inspect | Retrieve container ID, image digest, runtime config |
- Record image digest (e.g.,
sha256:...), not just mutable tags. - Record container ID, but treat it as ephemeral — it’s not globally unique.
- Minimize dependency on in-container paths; collect evidence from the host.
Outcome: Evidence linking the process instance to its immutable artifact — the container image digest.
Orchestrator evidence (e.g., Kubernetes)
The orchestrator adds intent: why this workload exists and under what identity it should run.
| Key | Source | Purpose |
|---|---|---|
k8s:pod:namespace | Kubelet / API | Defines administrative domain |
k8s:pod:serviceaccount | Pod spec | Maps workload to its logical identity |
k8s.pod:uid | Pod metadata | Unique immutable ID per Pod instance |
k8s:node:name | Kubelet registration | Links workload to node |
Collecting this data requires querying either:
- the kubelet API or CRI socket on the node (preferred for trust), or
- the Kubernetes API (if securely authenticated).
Attesters should avoid trusting in-container environment variables or downward API files, as those can be manipulated by the workload itself.
Node and OS provenance
The node provides the execution substrate. Establishing node identity ensures that attestation chains tie workloads to trusted infrastructure.
| Evidence | Source | Purpose |
|---|---|---|
| Hostname | /proc/sys/kernel/hostname | Node-level label |
| Kernel version | uname -r | Platform version tracking |
| OS version | /etc/os-release | Distribution fingerprint |
| Hardware UUID | /sys/class/dmi/id/product_uuid | Physical or virtual node identity |
Combine these facts to verify node fleet membership or hardware trust anchors.
Cloud instance metadata (optional)
When running in public clouds, host-level provenance can be enriched with cloud metadata.
These APIs provide verifiable information about the surrounding infrastructure, often cryptographically signed.
| Cloud | Endpoint | Notable fields |
|---|---|---|
| AWS | http://169.254.169.254/latest/meta-data/ | instance-id, region, ami-id, vpc-id |
| GCP | http://metadata.google.internal/computeMetadata/v1/ | instance/id, zone, project-id |
| Azure | http://169.254.169.254/metadata/instance | vmId, subscriptionId, resourceGroupName |
Access should be controlled and authenticated (IMDSv2 headers, Metadata-Flavor tokens). Evidence from IMDS proves the node’s identity, not the workload’s.
Bringing it together
Each process-level fingerprint expands into a richer contextual identity graph:
Process
├── Container → Image digest
├── Orchestrator → Namespace, ServiceAccount, Pod
├── Node → UUID, Kernel, OS
└── Cloud → Instance ID, Region, ProjectTogether, these layers form a structured representation of both intrinsic and environmental evidence, suitable for signing, evaluation, and identity issuance.
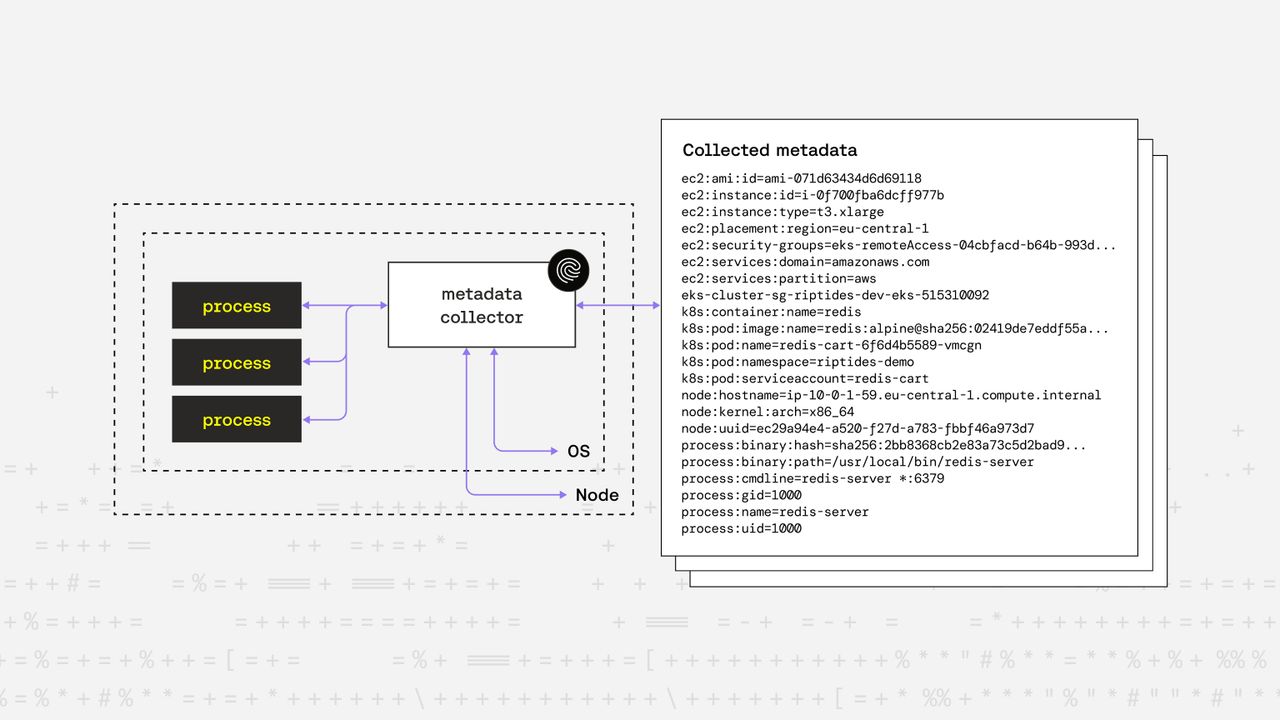
Dynamic Metadata Collection and Aggregation
From theory to implementation
Collecting attestation evidence sounds straightforward — read a few files from /proc, maybe query the container runtime, but in practice, workloads run in wildly diverse environments.
An attester must dynamically adapt its collection strategy to the runtime it’s observing while maintaining a consistent output format.
This requires an architecture built around modular metadata collectors, each specialized for a particular signal source: process, host, orchestrator, cloud, or hardware.
Collector architecture
The attester maintains a registry of collectors, each responsible for one logical source of evidence. Each collector implements two key methods:
- determine if the environment or data source is present.
- gather relevant metadata key–value pairs from that environment.
Collectors run concurrently and merge their outputs into a single, flattened metadata document.
Process-level collector
Works directly with the Linux kernel’s process introspection interfaces (/proc, sysfs) to extract immutable facts:
executable hash, cmdline, UID/GID, and capabilities, etc.
Environment collectors
- Container collector: maps process → container → image digest via cgroups and runtime sockets.
- Orchestrator collector: queries kubelet/CRI to attach namespace, service account, and pod related information.
- Node collector: reads DMI, hostname, OS release, and kernel version for node provenance.
- Cloud collectors: query metadata endpoints for instance IDs and region info.
Each collector adds context only when relevant and detected.
Aggregation pipeline
- Enumerate all collectors.
- Run detection concurrently.
- Collect evidence from applicable collectors.
- Merge outputs into a flattened metadata map with deterministic precedence.
Flattened metadata structure
ec2:ami:id=ami-071d634346d669118
ec2:instance:id=i-0f700fba6dcff977b
ec2:instance:type=t3.xlarge
ec2:placement:region=eu-central-1
ec2:security-groups=eks-remoteAccess-04cbfacd-b64b-993d-1e18-b5bcb500566b
ec2:services:domain=amazonaws.com
ec2:services:partition=aws
eks-cluster-sg-riptides-dev-eks-515310092
k8s:container:name=redis
k8s:pod:image:name=redis:alpine@sha256:02419de7eddf55aa5bcf49efb74e88fa8d931b4d77c07eff8a6b2144472b6952
k8s:pod:init-image:count=0
k8s:pod:name=redis-cart-6f6d4b5589-vmcgn
k8s:pod:namespace=riptides-demo
k8s:pod:serviceaccount=redis-cart
node:hostname=ip-10-0-1-59.eu-central-1.compute.internal
node:kernel:arch=x86_64
node:uuid=ec29a4e4-a520-f27d-a783-fbbf46a973d7
process:binary:hash=sha256:2bb8368cb2e83a73c5d2bad949702452987c570627de41d269997f99455473b2
process:binary:path=/usr/local/bin/redis-server
process:cmdline=redis-server *:6379
process:gid=1000
process:name=redis-server
process:uid=1000- Every key is globally unique, machine-readable, and human-auditable.
- Collectors operate independently; one failure does not stop the pipeline.
- Keys are sorted lexicographically, values normalized.
- The outcome is deterministic and portable.
Summary and Conclusion
Modern distributed systems depend on workloads that can authenticate securely, but secure authentication is impossible without trusted attestation. Before any workload receives an identity, the system must first prove what it is and where it runs. That proof comes from evidence, not configuration.
Across this post, we explored the foundations of workload attestation:
- Defining the problem — A workload is ultimately a process executing within an environment.
- Design goals — Determinism, collision resistance, least privilege, and portability.
- Process identity — Unique fingerprints from immutable process level information like uid/gid, executable hash.
- Environmental context — Container, orchestrator, node, and cloud metadata providing full context.
- Dynamic metadata gathering — Modular collectors combining these layers into a canonical evidence set.
Without attestation, every identity system is built on assumption. With it, identity becomes measurable, auditable, and revocable. Workload attestation is not just about security, it’s the foundation of verifiable trust. Every [certificate, every SPIFFE ID, every cryptographic handshake] ultimately depends on this ground truth.
If you enjoyed this post, follow us on LinkedIn and X for more updates. If you'd like to see Riptides in action, get in touch with us for a demo.