This post is the first in a short series about MCP servers and the security questions that come with them.
There is a lot of excitement around MCP right now, and that excitement is well deserved. MCP turns AI assistants into something much more practical than a simple chat interface. Instead of just generating text, they can interact with real systems by opening pull requests, updating tickets, querying internal services, or automating workflows that normally require jumping between tools.
For many teams this feels like the natural next step in automation. APIs made software programmable, and MCP provides a common interface that allows AI agents to interact with tools and services in a consistent way.
If you have not looked at the protocol itself yet, we previously wrote a short introduction that walks through the basics of MCP and how it works:
One of the reasons MCP adoption is moving quickly is that the protocol intentionally stays simple. It focuses on how agents and tools communicate and deliberately avoids prescribing how identity, authorization, or governance should be implemented around it. That flexibility makes MCP easy to adopt, but it also means those concerns are left to the surrounding platform.
And that is where things start to get interesting.
The pragmatic way MCP gets deployed
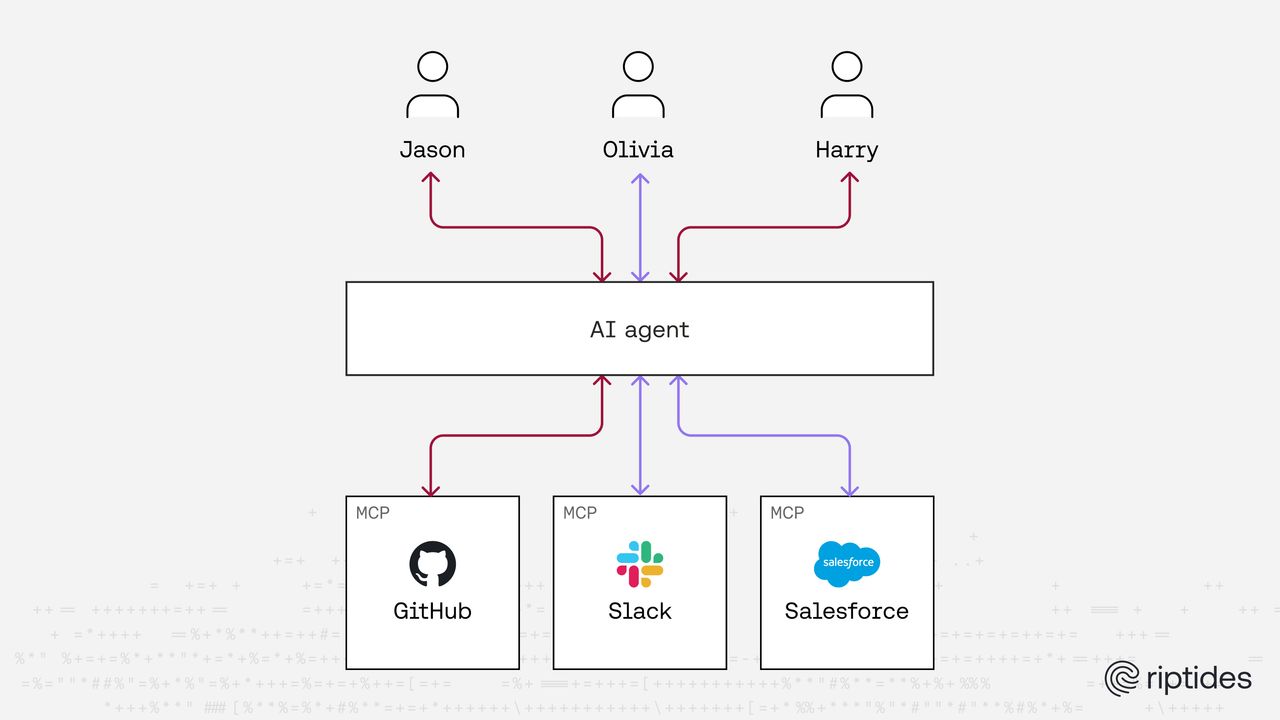
Most MCP deployments do not begin as a carefully designed security architecture. They usually start as experiments.
A team sets up a server and connects it to a few useful systems. GitHub is a common starting point, followed by something like a ticketing system or a cloud API. Once those connections are in place, the AI assistant suddenly becomes capable of performing real tasks. It can open pull requests, fetch logs, create tickets, and interact with internal systems that previously required manual steps.
In order for that to work, the MCP server needs credentials.
Someone therefore provides them, usually in the most straightforward way possible. Sometimes this is a service account, sometimes a personal access token, and sometimes an API key stored in configuration. At this stage the goal is not to design the perfect identity model but simply to make the workflow functional.
And once the system works, it tends to stay that way.
The AI becomes more useful, developers save time, and the integration remains in place without much further thought.
Nothing about this feels controversial.
The questions that appear later
The friction usually shows up later, and it tends to appear in fairly ordinary situations.
Someone notices a change in a repository or a cloud environment and wants to understand where it came from. The logs show that the action was performed by the identity attached to the MCP server, which is technically correct.
The next question, however, becomes harder to answer clearly. Which human actually initiated the action? Was it Alice using the assistant? Was it Bob running a different workflow? Was it triggered indirectly by an earlier request?
It is usually possible to reconstruct the answer by examining several different logs. The AI client might show who asked the original question, the repository history might reveal the sequence of changes, and infrastructure logs may provide additional context.
What often does not exist is a single place where the delegation chain is explicitly represented.
Instead, there is a trail of events that can be pieced together after the fact, but not necessarily a clear identity relationship that was enforced at the time the action occurred.
That gap is subtle, yet organizations tend to notice it quickly.
The shared credential problem
Another issue appears around permissions.
In most mature organizations human identities are tightly governed. People authenticate through SSO, access is tied to roles, and there may be approval flows or temporary elevation mechanisms when higher privileges are required.
Service accounts usually behave differently.
They exist to automate tasks, and automation tends to break when permissions are too restrictive. As a result, service accounts often accumulate capabilities over time.
When an MCP server relies on a single credential for multiple users, its authority gradually becomes the union of everyone’s needs. One developer may require repository access, another may need infrastructure visibility, and someone else might rely on the ability to create tickets or query internal services.
Nobody intentionally designs an overpowered identity.
Instead, the permissions grow gradually because removing them risks breaking workflows that people have come to depend on.
Security teams have been dealing with this pattern for years in the broader world of non-human identity. MCP does not introduce the problem, but it adds another layer where the same pattern can appear.
Identity becomes harder to explain
Lifecycle management is another place where things become slightly uncomfortable.
Human identities typically follow clear lifecycle controls. When someone joins a company they receive access, when they change roles their permissions are adjusted, and when they leave the organization their account is disabled.
Machine credentials rarely follow those same patterns.
If an MCP server’s permissions were expanded over time to support different workflows, those privileges tend to remain in place unless someone deliberately reviews and reduces them. The relationship between human lifecycle and machine authority therefore becomes indirect.
Some teams try to improve attribution by passing user tokens through the MCP layer instead of relying on a shared service account. This approach can help with visibility because downstream systems see the human identity rather than the machine identity.
At the same time it raises a different set of questions.
What exactly is being delegated to the MCP server? Is the server simply forwarding the request, or is it combining its own authority with the user’s authority? Is the delegation limited to a specific session or scope, or is it effectively open ended?
In many real deployments these questions do not have clearly defined answers. The system functions correctly, but the delegation model remains more implicit than explicit.
Communication security is only part of the story
Another part of the puzzle is the connection between agents and MCP servers themselves.
As soon as MCP servers begin interacting across services or environments, the system starts to resemble workload-to-workload communication in distributed systems. At that point questions about authentication, encryption, and trust boundaries become important as well.
We explored that aspect earlier when discussing how MCP communication can be secured using strong workload identity and mutual authentication:
Establishing trust between agents and MCP servers is an important step.
However, transport security only addresses part of the challenge. Even if every connection is encrypted and every machine proves its identity, the system still needs to represent who the machine is acting for.
The identity of the workload and the identity of the human behind the request are two different pieces of information, and both of them matter.
Machines acting for people
This is where things become particularly interesting.
In traditional systems two identity models have evolved somewhat independently. OAuth based systems are good at representing delegated user authorization and answering questions such as who granted access and what scope was approved.
Workload identity systems such as SPIFFE focus on machines and provide strong cryptographic identity for services communicating with each other.
In earlier posts we explored how these two worlds are starting to converge, especially in environments where AI agents and automation interact with real systems:
- SPIFFE Meets OAuth2: Current Landscape for Secure Workload Identity in the Agentic AI Era
- Bringing SPIFFE to OAuth for MCP: Secure Identity for Agentic Workloads
As agent based workflows become more common, machines increasingly act on behalf of people. Systems therefore need to represent both identities at the same time: the machine identity that executes the request and the human identity whose authority is being delegated.
When those two pieces are not clearly defined together, governance becomes much harder to reason about.
Why this matters now
None of these issues feel dramatic during day-to-day use.
The AI assistant works, tasks are completed faster, and engineers spend less time switching between tools.
The tension usually appears during audits, security reviews, or incident investigations, when someone needs to explain how authority actually flowed from a human, through an AI assistant, into a production system.
At that point the architecture often turns out to be more informal than expected.
This is not because teams are careless, but because MCP adoption is moving faster than the identity models around it.
What this series will explore
This series will look more closely at that identity layer.
In the next posts we will examine how delegation actually works in MCP based systems, why traditional non-human identity controls only partially address the problem, and how stronger patterns might emerge as AI agents become a normal part of software systems.
For now, the key observation is simple.
MCP introduces a new layer between people and the systems they interact with. Whenever a new layer appears in the identity chain, it is worth treating it as a governance boundary rather than just an implementation detail.
If you enjoyed this post, follow us on LinkedIn and X for more updates. If you'd like to see Riptides in action, get in touch with us for a demo.